Introducing musts
I built musts to move project-specific validation rules out of my head and into the repository.
musts is a small Rust CLI that tells a coding agent exactly what it still needs to verify after a change. Each project declares its own checks in MUSTS.yml. The agent runs musts validate, gets the list, runs it, records evidence, and repeats until the list is empty.
Repo: github.com/bitomule/musts. Now the story behind it.
I have been using coding agents more and more during the last months and there was one part of the workflow that was still too manual.
The agent could do the work. The problem was how to know what validations came next.
You can write in AGENTS.md that every code change must compile, pass tests, and include verification before the agent calls the task complete. That helps, but the behavior is not deterministic. Most of the time the agent will follow the rule. Sometimes it will not. Not because it tries to cheat, but because a rule in a context file is still something the model has to remember at the right moment.
Compiling is also the easy case.
Real projects have checks that are not global. If a view changes, review the UI with a specific skill. If a module changes, run an end-to-end flow. If the build number changes, check the semantic format. If a fixture changes, regenerate a snapshot.
Every project has a different list. The list also grows over time.
When I write the change myself, those checks are easier to keep in the loop. I know why I am touching a file and I have more project context loaded in my head. That does not mean I never forget, but the failure mode is different.
With agents, I was still the person remembering the project rules.
If I told the agent to run a validation, it did. That was not the problem. The problem was that I had to remember the validation, decide if it applied, prompt the agent, and ask for evidence.
What I tried first
The first thing I did was write more of this down.
I put project instructions in AGENTS.md. I created skills for repeated validation steps. I wrote down the checks that tended to come back again and again, so I would not have to explain them from scratch every time.
That helped a lot. Skills made repeated work cheaper. Instructions gave the agent a better default behavior. I still use both.
But the loop still depended on my supervision.
Before I could call an agent task resolved, I had to inspect the changes and remember which validations might apply.
Then I had to decide which ones were actually needed, prompt the agent to run them, and ask it to produce evidence.
It worked, but it was slow. It also limited automation. If I wanted agents to do more work with less supervision, the validations could not live in my head.
I needed those obligations to live in the project instead.
What I wanted
I wanted the agent to ask the project what still needed checking.
Not in natural language. Not as another long instruction file. I wanted a small CLI that could look at the repository, detect what had changed, and return the validations that were still pending.
The agent would run the command, follow the report, record evidence, and run the command again.
When the report was empty, the project had no pending validations for that task.
That is what I built. I called it musts.
How it works
I will not turn this post into a README. The repository is a better place for that. But the decisions that mattered are worth saying out loud, because they shaped the tool more than the implementation details did.
The first decision was that it had to be a CLI. A CLI saves tokens, has deterministic behavior, and sits outside the agent. The agent calls musts validate, reads the report, acts on it, records evidence with musts evidence, and calls musts validate again.
The second decision was that checks had to be easy for humans to maintain. I considered Markdown because it is pleasant to write and agents read it well. But Markdown became ambiguous as soon as checks needed options. YAML was boring, but represented the rules better.
Here is what a MUSTS.yml looks like in practice:
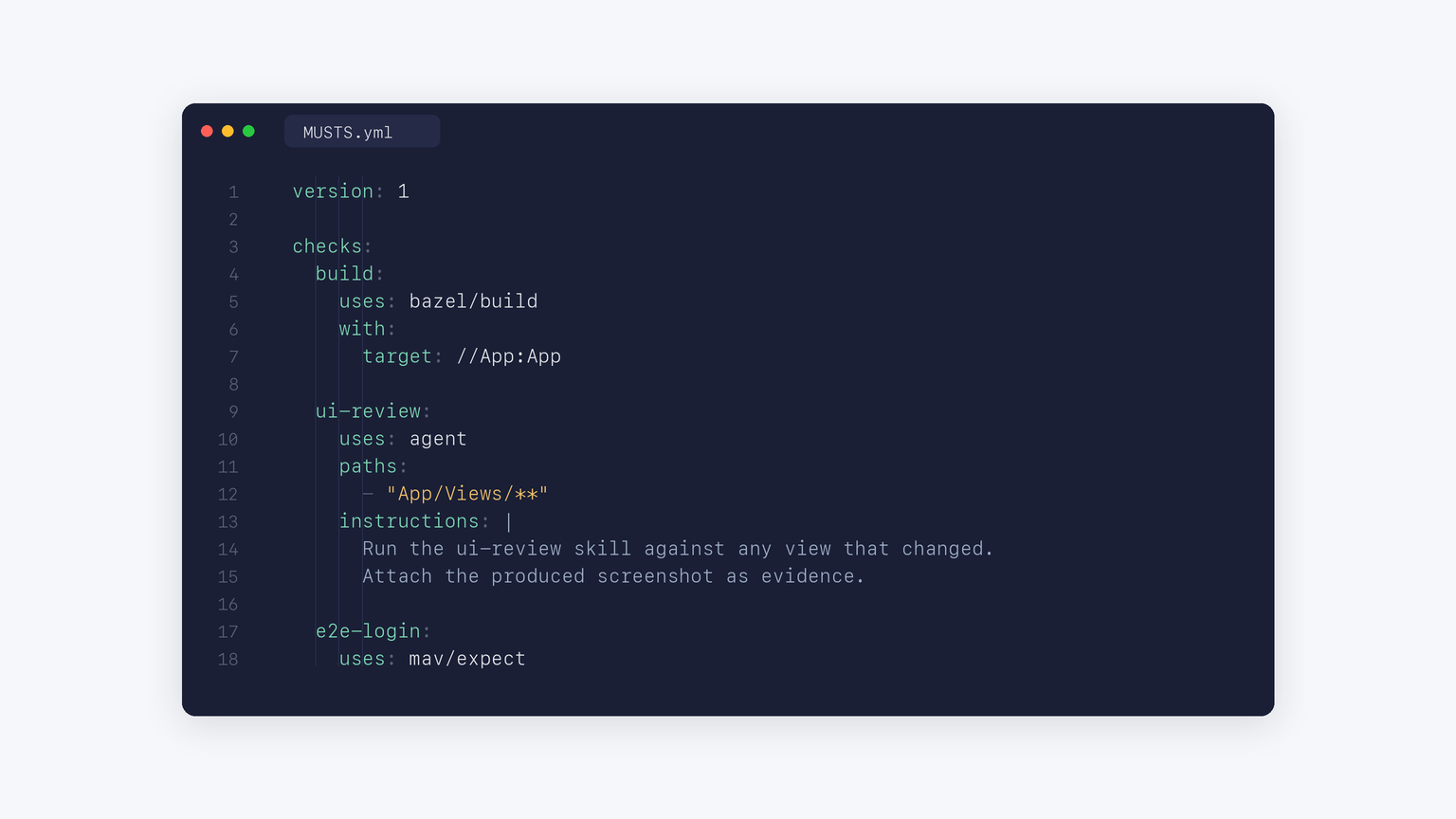
Three checks, three different capabilities. The first runs Bazel. The second is an agent contract: when something inside App/Views/ changes, the agent has to run a skill and attach evidence. The third delegates to MAV, which validates an iOS flow.
The third decision was that the normal output had to be boring and easy to skim. musts still uses JSON where JSON makes sense: the extension protocol is JSON, and musts validate --json exists for tools. But the normal report is plain text: task id, title, capability, instructions, required evidence, and the completion rule.
This is what one pending task looks like in a real musts validate report:
Task: cargo-fmt-root
Title: Run `cargo fmt --check`
Extension: cargo/fmt
Satisfies:
- root/fmt
Instructions:
1. Run `cargo fmt --check` from the workspace root.
2. Capture combined stdout/stderr to a file outside the workspace.
3. Record the result with `musts evidence cargo-fmt-root --text "…" --asset <log>`.
Evidence required:
- text (required): State whether `cargo fmt --check` reported diffs.
- log (required): Stdout/stderr from `cargo fmt --check`.No JSON to parse, no nested structures. The agent reads the next obligation and acts on it.
The fourth decision was that the system had to be extensible. Some checks are simple cargo commands. Some need MAV. Some need a skill. Some need domain-specific evidence. The core should not know every rule. It should know how to discover checks, detect what changed, ask the right capability what has to be done, and record whether the evidence satisfied the obligation.
That is the basic loop.
What I learned building it
The first thing I learned is that agents are consistent at using musts.
That mattered more than the design in my head. If the agent runs musts validate, follows the report, records evidence, and runs musts validate again, the loop is usable. The tool does not need the agent to understand the whole project. It needs the agent to follow the next concrete obligation.
The second thing I learned is that musts can run in CI. The repository already has a musts validate self-check in GitHub Actions, and the ledger lock makes that possible without carrying the whole local evidence store around. I have not yet explored the more interesting version, where an agent acts on that CI feedback, but the boundary is there.
The third thing I learned is that validations split into two groups.
Some checks are deterministic. cargo fmt --check either reports diffs or it does not. A build either succeeds or it does not. Other checks are closer to reminders for the agent: review this UI, validate this flow, attach evidence that this expectation still holds.
Those are still useful, but they are not the same as a compiler check. musts has to support both.
Some checks are hard checks where the capability can validate the evidence mechanically. Others are softer obligations where the value is making the agent stop, look, and record what it did.
The fourth thing I learned is more technical. Walking a repository tree is harder than it sounds.
musts has to find manifests, understand which files belong to which scope, and ignore the right generated or external paths.
It also has to handle nested manifests, keep hashes stable across platforms, and avoid invalidating checks because unrelated files changed.
I had to iterate on that more than once. Paths filters, .mustsignore, workspace resolution, portable scope hashes, and ledger refreshes all came from places where the first simple version was not enough.
That part is not glamorous, but it makes the loop useful. If the tool cannot answer “what changed, and which obligations does that affect?” consistently, the rest does not matter.
The discipline of the loop
What I want from musts is not a smarter agent.
I want fewer project rules living in my head. I want the repository to say what validations apply when a part of the code changes. I want the agent to ask the project what is still pending instead of waiting for me to remember it.
That is the important shift for me. AGENTS.md and skills still matter, but they are not the source of truth for completion. They are context and procedures. The source of truth is the validation loop: what changed, which checks apply, what evidence was recorded, and whether anything is still pending.
That does not remove judgment. Some evidence will still be soft. Some validations will still need an agent, a simulator, a screenshot, a report, or a human review. But it moves the responsibility to the right place.
The project defines the obligation. The agent follows it. I review the result instead of rebuilding the checklist from memory every time.
That is why the rule in the README is the rule I care about:
The task is not done until musts validate is empty.